Chibany's Mystery Bentos
The Weight of the Matter
It’s a new semester at the university, and Chibany’s students have been bringing them bentos again. But this time, something is different.
Last semester, the bento boxes were transparent. So Chibany could see whether there was tonkatsu or hamburger inside. But this semester, the bento boxes are opaque. Thus, Chibany can’t see what is inside when they receive the bento. They want to know IMMEDIATELY what the meal is, but it would be extremely rude to open the bento box as the students are watching. Thankfully, Chibany is curious, and they’re a probabilist.
So they hatch a plan: weigh the bentos.
Tonkatsu bentos are hearty and heavy. Hamburger bentos are lighter. If they record the weights, maybe they can figure out what they’ve been receiving, and even predict what’s coming next.
Overheard Conversation
One afternoon, while Chibany is napping, they overhear two students chatting nearby:
Student 1: “I’ve been bringing Chibany tonkatsu most days. It’s their favorite!” Student 2: “Me too! Though sometimes I bring hamburger when the cafeteria runs out of tonkatsu.” Student 1: “Yeah, I’d say I bring tonkatsu like… seven times out of ten?” Student 2: “Same! About 70% tonkatsu, 30% hamburger.”
Chibany smiles. So there is a pattern! But they decide to continue their experiment anyway. Can they discover this 70-30 split just from weighing the bentos?
Week One: Something Strange
Chibany weighs their first week of bentos and records the measurements:
Monday: 520g
Tuesday: 348g
Wednesday: 505g
Thursday: 362g
Friday: 488gThey calculate the average: 441 grams.
“Hmm,” they think, “that’s odd. Last semester, tonkatsu bentos weighed about 500g and hamburger bentos weighed about 350g. But 441g is right in the middle! Am I getting medium-sized bentos?”
They weigh more bentos over the next few weeks:
Week 2: 355g, 510g, 492g, 345g, 515g
Week 3: 498g, 358g, 505g, 362g, 490g
Week 4: 352g, 488g, 508g, 355g, 495gAfter a month, they have 20 measurements. The average is still around 445g.
But something doesn’t add up…
The Paradox Revealed
Chibany plots their measurements on a histogram:
| |
Click to show visualization code
| |
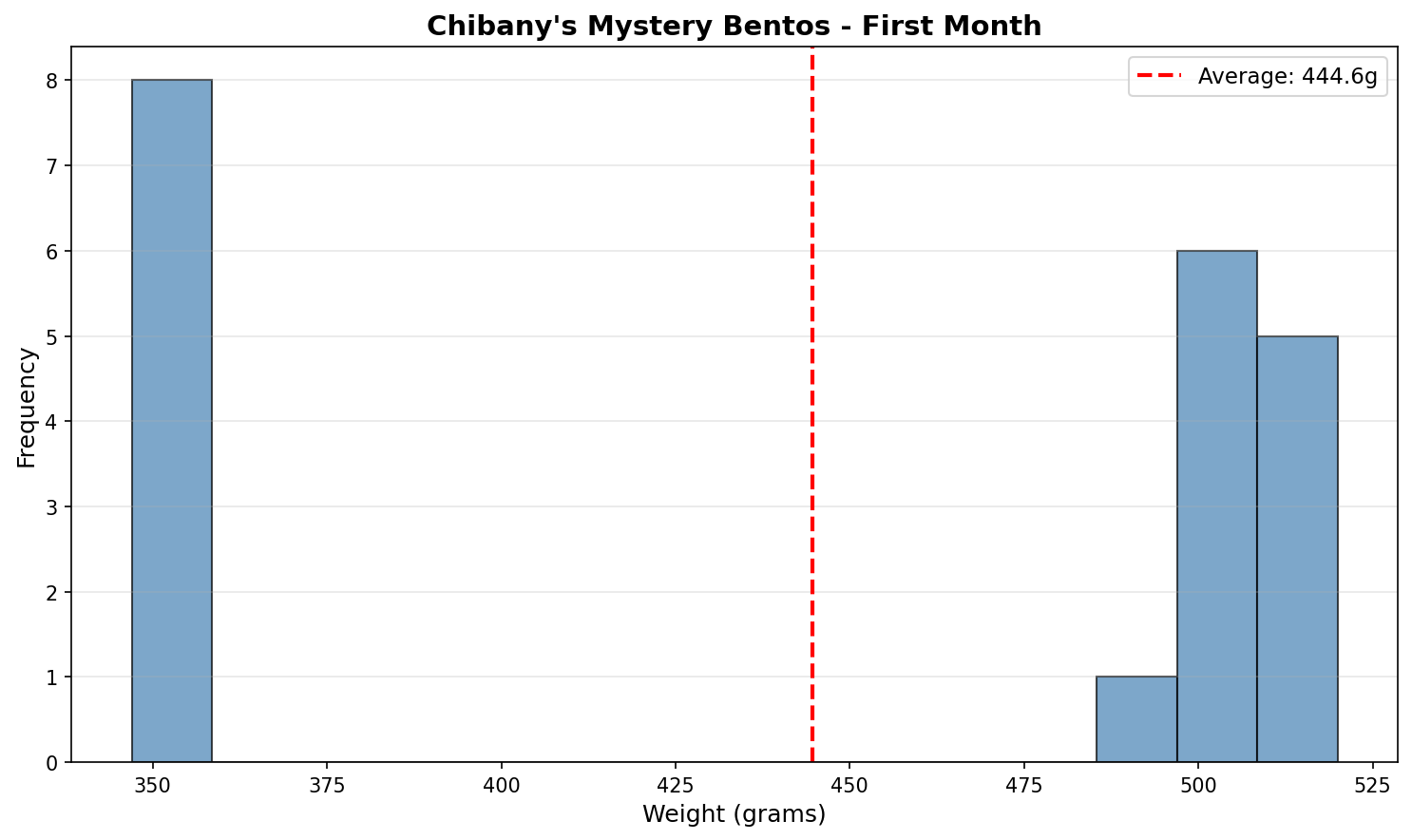
Output:
Average weight: 445.4g
Weights near 350g: 6
Weights near 500g: 14
Weights near 445g: 0They stare at the plot. Something is very wrong.
Most weights cluster around 350g (hamburger range). Most others cluster around 500g (tonkatsu range). But ZERO measurements are near 445g (the average)!
The Paradox
The average weight is a weight that almost never occurs!
This seems impossible. How can the average be 445g when no bento weighs anywhere near 445g?
The Resolution: Expected Value
Chibany has an insight. They’re not receiving “medium bentos.” They’re receiving a mixture of heavy tonkatsu bentos and light hamburger bentos!
Looking at the data more carefully:
- About 14 out of 20 measurements are near 500g (tonkatsu)
- About 6 out of 20 measurements are near 350g (hamburger)
That’s roughly:
- 70% tonkatsu (θ = 0.7), just like the students said!
- 30% hamburger (θ = 0.3)
Now the 445g average makes sense! It’s not that individual bentos weigh 445g. It’s that the long-run average of the mixture is:
$$\text{Average weight} = (0.7 \times 500\text{g}) + (0.3 \times 350\text{g}) = 350 + 105 = 455\text{g}$$
Their observed average of 445g is close to the theoretical 455g. The difference is just random variation from a small sample.
This is called the expected value, written $E[X]$.
What Is Expected Value?
In plain English: Expected value is what you’d get “on average” if you repeated something many, many times.
For Chibany’s bentos:
- 70% of days he gets tonkatsu (500g)
- 30% of days he gets hamburger (350g)
- On average over many days, his bento weighs: (0.7 × 500) + (0.3 × 350) = 455g
The mathematical definition: Expected value is the weighted average of all possible outcomes, where the weights are the probabilities.
For a discrete random variable $X$ that can take values $x_1, x_2, \ldots, x_n$ with probabilities $p_1, p_2, \ldots, p_n$:
$$E[X] = \sum_{i=1}^{n} p_i \cdot x_i$$
Breaking this down:
- $p_i$ = probability of outcome $i$
- $x_i$ = value of outcome $i$
- $\sum$ = “add them all up”
In Chibany’s case:
- $X$ = weight of a bento
- $x_1 = 500$ (tonkatsu weight) with probability $p_1 = 0.7$
- $x_2 = 350$ (hamburger weight) with probability $p_2 = 0.3$
Therefore: $$E[X] = 0.7 \times 500 + 0.3 \times 350 = 455\text{g}$$
Three Key Insights
1. Expected value ≠ “expected” in the everyday sense
You shouldn’t “expect” any single bento to weigh exactly 455g. In fact, almost no bento weighs 455g! The term “expected value” is a bit misleading. It really means “long-run average.”
2. Expected value is the center of mass
Imagine the histogram balanced on a seesaw. Where would you put the fulcrum so it balances? At the expected value! It’s the distribution’s “center of gravity.”
3. Expected value hides the structure
Knowing $E[X] = 455\text{g}$ doesn’t tell you there are two distinct types of bentos. You lose the bimodal structure (two peaks). That’s why we’ll need more tools (like variance and mixture models) to fully understand distributions.
Common Misconceptions About Expected Value
Common Misconceptions
Misconception 1: “Expected value is the most likely value” ❌ False! In Chibany’s case, E[X] = 455g, but the most likely values are 350g or 500g. Zero bentos weigh 455g!
✓ Correct: Expected value is the long-run average, not the most probable outcome.
Misconception 2: “Expected value is what I should expect to see next” ❌ False! The next bento will weigh ~350g or ~500g, not 455g.
✓ Correct: Expected value describes the distribution’s center, not individual outcomes.
Misconception 3: “Expected value fully describes the distribution” ❌ False! Two very different distributions can have the same expected value:
- Distribution A: All bentos weigh exactly 455g
- Distribution B: 70% weigh 500g, 30% weigh 350g
Both have E[X] = 455g, but they’re completely different!
✓ Correct: Expected value is just the first moment. We also need variance (spread), shape, etc.
Misconception 4: “Expected values can’t be impossible outcomes” ❌ False! Expected value can be a value that’s impossible to observe.
Example: Expected value of a fair die is $E[X] = 3.5$, but you can never roll 3.5!
✓ Correct: Expected value is a mathematical average, not necessarily a realizable outcome.
Visualizing Expected Value as Balance Point
Let’s see why E[X] is called the “balance point” by trying different fulcrum positions:
Click to show visualization code
| |
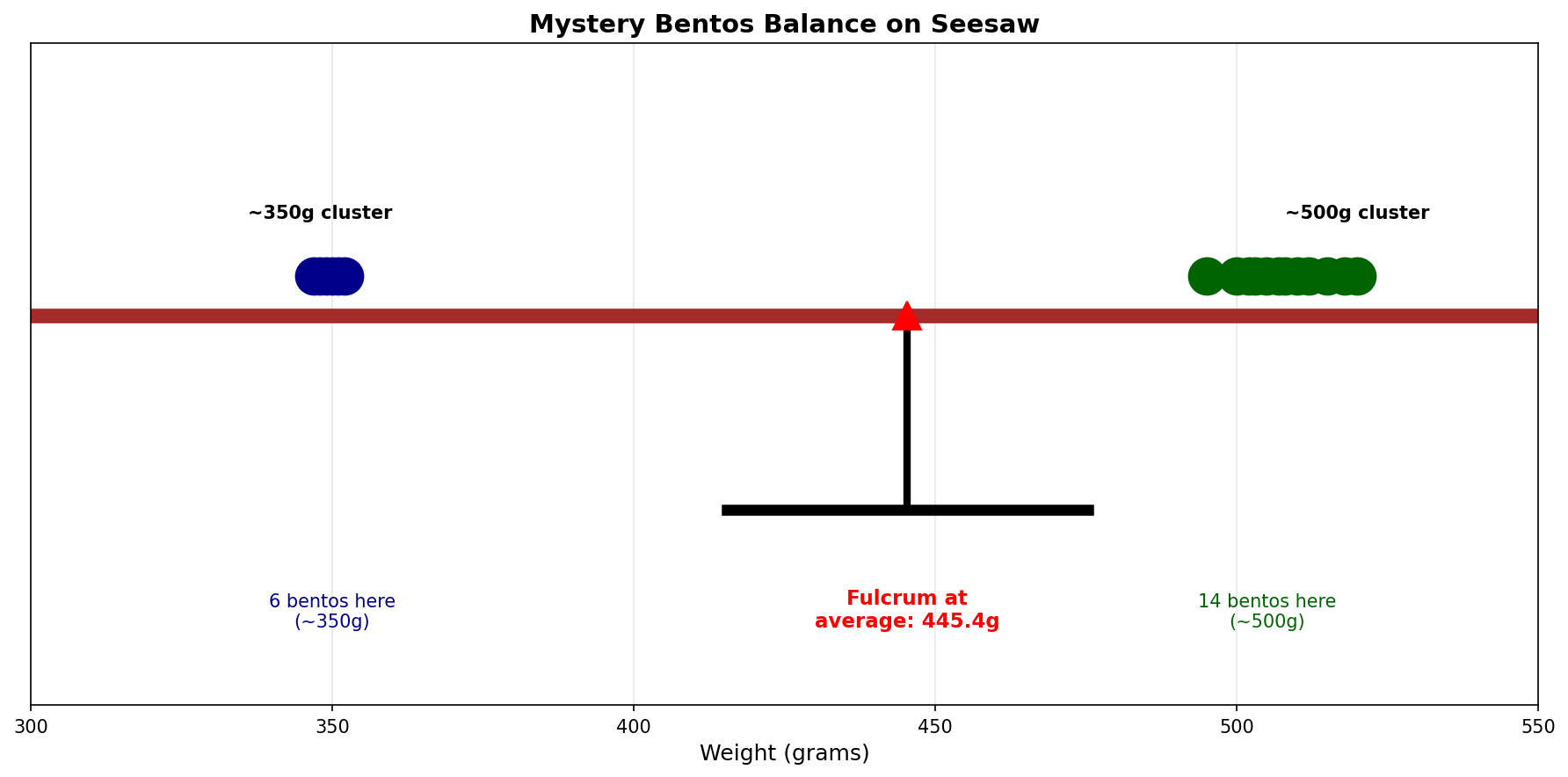
The expected value E[X] = 455g is the unique position where the distribution balances.
Think of it like a seesaw at a playground:
- When the fulcrum is at 400g, the heavy tonkatsu side (70% probability at 500g) outweighs the hamburger side, tipping the seesaw to the right
- When the fulcrum is at 480g, the hamburger side (despite being only 30%) is so far away (130g!) that it has more “leverage,” tipping the seesaw to the left
- Only at E[X] = 455g does everything balance perfectly. The hamburger’s distance (105g away) times its weight (30%) equals the tonkatsu’s distance (45g away) times its weight (70%): both equal 31.5
Simulation Validation
Let’s verify this computationally. If Chibany’s students are randomly choosing 70% tonkatsu and 30% hamburger, what should happen over many days?
| |
Click to show visualization code
| |
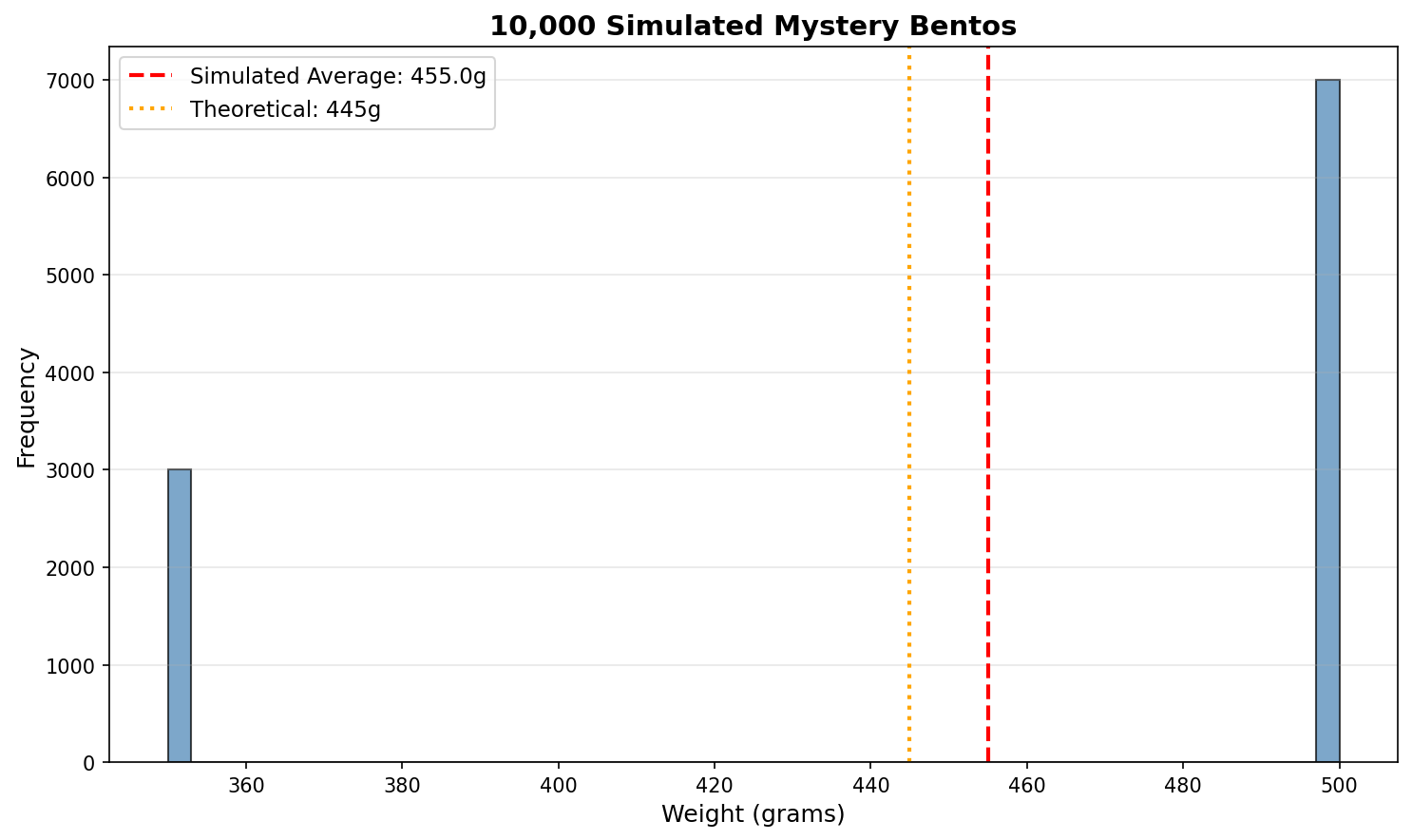
Output:
Observed average: 455.5g
Theoretical E[X]: 455.0g
Difference: 0.5g
Actual counts:
Tonkatsu: 701 (70.1%)
Hamburger: 299 (29.9%)The long-run average converges to the expected value! This is the Law of Large Numbers in action.
Properties of Expected Value
Expected value has some useful mathematical properties that will be crucial for mixture models:
Linearity
Property 1: $E[aX + b] = aE[X] + b$
If you scale and shift a random variable, its expected value scales and shifts the same way.
Example: Chibany switches to measuring in ounces instead of grams. 1 gram ≈ 0.035 ounces, so weight in oz = weight in g × 0.035
$$E[\text{weight in oz}] = 0.035 \times E[\text{weight in g}] = 0.035 \times 455 \approx 15.9\text{ oz}$$
Property 2: $E[X + Y] = E[X] + E[Y]$
The expected value of a sum is the sum of expected values. This holds even if X and Y are dependent!
Example: If Chibany receives 5 bentos in one day, the expected total weight is: $$E[\text{total}] = E[X_1] + E[X_2] + E[X_3] + E[X_4] + E[X_5]$$ $$= 5 \times E[\text{single bento}] = 5 \times 455 = 2275\text{g}$$
Why Linearity Matters
This linearity property is what makes mixture models work!
When we have a mixture: $$E[X] = \theta \cdot E[X_{\text{tonkatsu}}] + (1-\theta) \cdot E[X_{\text{hamburger}}]$$
We can compute the expected value of a complex mixture by just taking a weighted average of the component expected values.
This will be crucial in Chapter 5 when we study Gaussian mixtures!
Modeling the Mixture with GenJAX
Now let’s see how to express Chibany’s bento mixture as a generative model using GenJAX! This builds directly on what you learned in Tutorial 2.
The Generative Process
Recall from Tutorial 2 that we express random processes using generative functions. Here’s Chibany’s bento selection process:
| |
What’s happening here?
flip(0.7)flips a weighted coin: 70% True (tonkatsu), 30% False (hamburger)@ "type"gives this random choice an address (like you learned in Tutorial 2, Chapter 3)jnp.where(is_tonkatsu, 500.0, 350.0)returns 500g if tonkatsu, 350g if hamburger — a single deterministic value computed from the randomtype, so it is the model’s return value (we only give addresses to random choices, like"type", not to deterministic results)
This is the generative model for Chibany’s bentos!
Simulating from the Model
Let’s simulate 1000 bentos and calculate the average weight, just like Chibany’s experiment:
| |
Output:
Simulated average weight: 451.5g
Theoretical E[X]: 455.0g
Counts:
Tonkatsu (500g): 677 (67.7%)
Hamburger (350g): 323 (32.3%)The simulated average is very close to the theoretical expected value!
Connecting to Expected Value
Remember the expected value formula: $$E[X] = 0.7 \times 500 + 0.3 \times 350 = 455\text{g}$$
GenJAX simulates this process:
- Each simulation samples from the generative process
- The average of many samples approximates the expected value
- This is Monte Carlo estimation: using simulation to approximate mathematical expectations
Examining Individual Traces
One power of GenJAX is that we can inspect what the model generates. Let’s look at a few traces:
| |
Output:
Bento 1: Hamburger → 350g
Bento 2: Hamburger → 350g
Bento 3: Tonkatsu → 500g
Bento 4: Tonkatsu → 500g
Bento 5: Hamburger → 350gEach trace records both the type (the random choice) and the weight (the return value). This is the trace structure you learned about in Tutorial 2, Chapter 3!
GenJAX vs. Pure Python
Why use GenJAX instead of pure Python/NumPy?
Right now, the GenJAX version might seem like overkill. But here’s what we gain:
- Explicit generative model: The code reads like the probabilistic story
- Addressable choices: Every random decision has a name (
"type","weight") - Conditioning (coming soon!): We can ask “What if I observe weight = 425g?”
- Inference (Chapters 4-6): We can learn parameters from data
- Composability: Easy to extend (add more bento types, add weight variation, etc.)
As the models get more complex (Chapters 3-6), GenJAX will become essential!
Preview: What’s Missing?
This model captures the discrete mixture (tonkatsu vs. hamburger) but notice what it doesn’t capture:
- Real tonkatsu bentos don’t weigh exactly 500g - they vary (488g, 505g, 515g, etc.)
- Real hamburger bentos don’t weigh exactly 350g - they vary too (348g, 358g, 362g, etc.)
To model this within-category variation, we need:
- Continuous distributions (Chapter 2)
- Gaussian distributions (Chapter 3)
- Gaussian mixtures (Chapter 5)
That’s where we’re headed!
But We’re Not Done Yet…
Chibany stares at their histogram. They understand the average now. 455g makes sense as a mixture. But something still bothers them.
Look at these two measurements:
- 488g (probably tonkatsu)
- 362g (probably hamburger)
But what about 425g? It’s right in the middle. Is it a heavy hamburger or a light tonkatsu?
And another thing: the weights aren’t exactly 500g and 350g. They vary! Some tonkatsu bentos weigh 520g, others 485g. Why?
Chibany realizes:
Discrete categories aren’t enough. Weight is CONTINUOUS.
There aren’t just two possible values (350g and 500g). There are infinitely many possible weights between 340g and 520g.
The histogram shows this: the data has spread within each category.
To handle this, Chibany needs a new kind of probability: continuous probability distributions.
And the most important continuous distribution? The Gaussian (also called the Normal distribution). That’s what creates the bell-curve shapes within each category.
But first, we need to understand the fundamental framework for handling continuous probability…
Summary
Chapter 1 Summary: Key Takeaways
The Mystery:
- Chibany receives mystery bentos and can only weigh them
- Average weight is 445g, but almost no bento weighs 445g!
- The histogram shows two peaks (350g and 500g), not one at 445g
The Resolution: Expected Value
- Chibany receives a mixture: 70% tonkatsu (~500g), 30% hamburger (~350g)
- Expected value is the weighted average of outcomes: $$E[X] = \sum_{i} p_i \cdot x_i = 0.7 \times 500 + 0.3 \times 350 = 455\text{g}$$
Key Concepts:
- Expected value ≠ “expected” outcome: It’s the long-run average, not the most likely value
- Balance point: E[X] is where the distribution would balance on a seesaw
- Hides structure: E[X] alone doesn’t tell you about the bimodal shape or spread
- Law of Large Numbers: Sample averages converge to E[X] as sample size grows
Important Properties:
- Scaling: $E[aX + b] = aE[X] + b$
- Linearity: $E[X + Y] = E[X] + E[Y]$ (works even for dependent variables!)
- Mixture: $E[\text{mixture}] = \theta E[X_1] + (1-\theta) E[X_2]$
What We Still Need:
- Measure of spread (variance/standard deviation): Coming in Chapter 4
- Continuous probability framework: Coming next!
- Understanding of within-category variation: Why isn’t every tonkatsu exactly 500g?
Looking Ahead: Next chapter tackles the fundamental challenge: how to handle probability when there are infinitely many possible values (continuous distributions).
Practice Problems
Problem 1: Menu Expansion
Chibany’s students start bringing a third type of bento: sushi (600g). Now the proportions are:
- 50% tonkatsu (500g)
- 30% hamburger (350g)
- 20% sushi (600g)
What is the expected bento weight?
Problem 2: Multiple Bentos
If the proportions are 70% tonkatsu (500g) and 30% hamburger (350g), what is the expected total weight of 10 bentos?
Problem 3: Conceptual Challenge
Chibany observes that their bentos have E[X] = 455g. Their colleague receives bentos from a different cafeteria and also observes E[X] = 455g.
Does this mean they’re receiving the same distribution of bentos? Why or why not?