The Gaussian Distribution
The Bell Curve
After learning about the uniform distribution in Chapter 2, Chibany realizes something: real measurements rarely spread evenly across a range. When they measure 1000 tonkatsu bentos carefully, the weights don’t spread uniformly between 495g and 505g. Instead, most cluster near 500g, with fewer and fewer measurements appearing as you move away from that center value.
This pattern appears everywhere in nature:
- Heights of people
- Measurement errors
- Test scores
- Daily temperatures
- And yes, bento weights!
This is the Gaussian distribution (also called the Normal distribution), and it’s arguably the most important probability distribution in statistics.
The characteristic “bell curve” shape captures a fundamental pattern: most values cluster near the mean, with a smooth, symmetric decline as you move away.
The Gaussian Probability Density Function
The PDF for a Gaussian distribution is:
$$p(x|\mu, \sigma^2) = \frac{1}{\sigma\sqrt{2\pi}} \exp\left(-\frac{1}{2\sigma^2}(x-\mu)^2\right)$$
Don’t panic! You don’t need to memorize this formula. GenJAX handles it for you. But let’s understand what the parameters mean:
Two Parameters Control the Shape
1. Mean (μ, “mu”): The center of the bell curve
- This is where the peak occurs
- It’s also the expected value: E[X] = μ
- Changing μ shifts the entire curve left or right
2. Variance (σ², “sigma squared”): The spread of the curve
- Larger variance → wider, flatter bell
- Smaller variance → narrower, taller bell
- Standard deviation (σ) is the square root: σ = √(σ²)
In Plain English
The Gaussian PDF says: “Values near μ are most likely, and likelihood drops off smoothly as you move away. How quickly it drops off depends on σ².”
The complicated-looking exponential term $\exp\left(-\frac{1}{2\sigma^2}(x-\mu)^2\right)$ creates the bell shape. The key insight:
- When x = μ (at the mean), the exponent is 0, so exp{0} = 1 (maximum height)
- As x moves away from μ, $(x-\mu)^2$ grows, making the exponent more negative
- Negative exponents shrink toward 0, creating the tails
The 68-95-99.7 Rule
One of the most useful properties of the Gaussian distribution:
68% of values fall within 1 standard deviation of the mean
- That is, between μ - σ and μ + σ
95% of values fall within 2 standard deviations
- Between μ - 2σ and μ + 2σ
99.7% of values fall within 3 standard deviations
- Between μ - 3σ and μ + 3σ
Why This Matters
If Chibany’s tonkatsu bentos follow N(500, 4) (mean 500g, variance 4g²), then:
- Standard deviation σ = √4 = 2g
- 68% of bentos weigh between 498g and 502g (500 ± 2)
- 95% weigh between 496g and 504g (500 ± 4)
- 99.7% weigh between 494g and 506g (500 ± 6)
Any bento lighter than 494g or heavier than 506g would be unusual (less than 0.3% probability).
Gaussian Distribution in GenJAX
Let’s model the tonkatsu bento weights using a Gaussian distribution:
| |
Output:
Simulated mean: 499.98g
Simulated std dev: 2.01g
Theoretical mean: 500.00g
Theoretical std dev: 2.00gPerfect match! The Law of Large Numbers strikes again.
Verifying the 68-95-99.7 Rule
| |
Output:
Within 1σ (498-502g): 68.2% (expect 68%)
Within 2σ (496-504g): 95.4% (expect 95%)
Within 3σ (494-506g): 99.7% (expect 99.7%)The empirical rule holds!
Visualizing Different Gaussian Distributions
Let’s see how μ and σ affect the shape:
| |
Click to show visualization code
| |
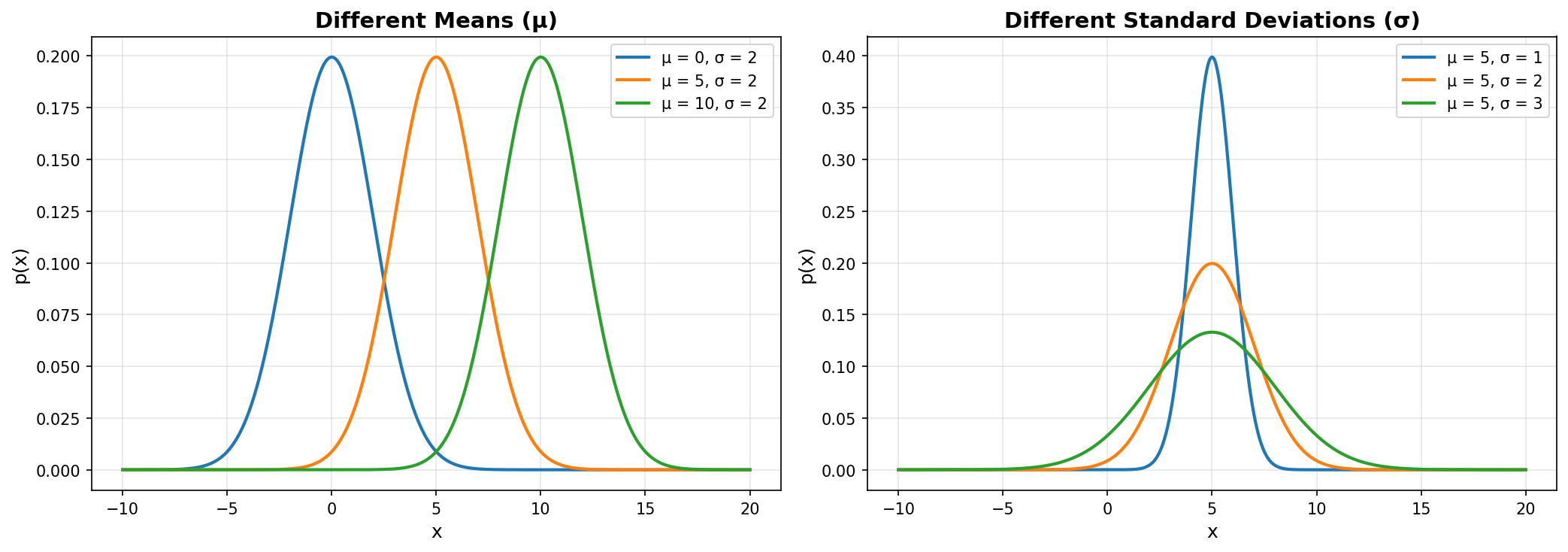
Key observations:
- Left plot: Changing μ shifts the curve horizontally (location changes)
- Right plot: Changing σ changes the spread (smaller σ = taller/narrower, larger σ = shorter/wider)
Back to Chibany’s Bentos
Remember the mystery from Chapter 1? Now we can model it more realistically:
Tonkatsu bentos: N(500, 4) (mean 500g, std dev 2g) Hamburger bentos: N(350, 4) (mean 350g, std dev 2g)
Note: Illustrative Code
The code below shows the concept of a mixture model. Due to JAX’s functional design, the actual working implementation uses advanced techniques (see the interactive Colab notebook for the full working version).
For learning purposes, this simplified version demonstrates the modeling logic.
| |
Output:
Average weight: 455.1g
Expected value: 455.0gNow let’s visualize this mixture:
| |
Click to show visualization code
| |
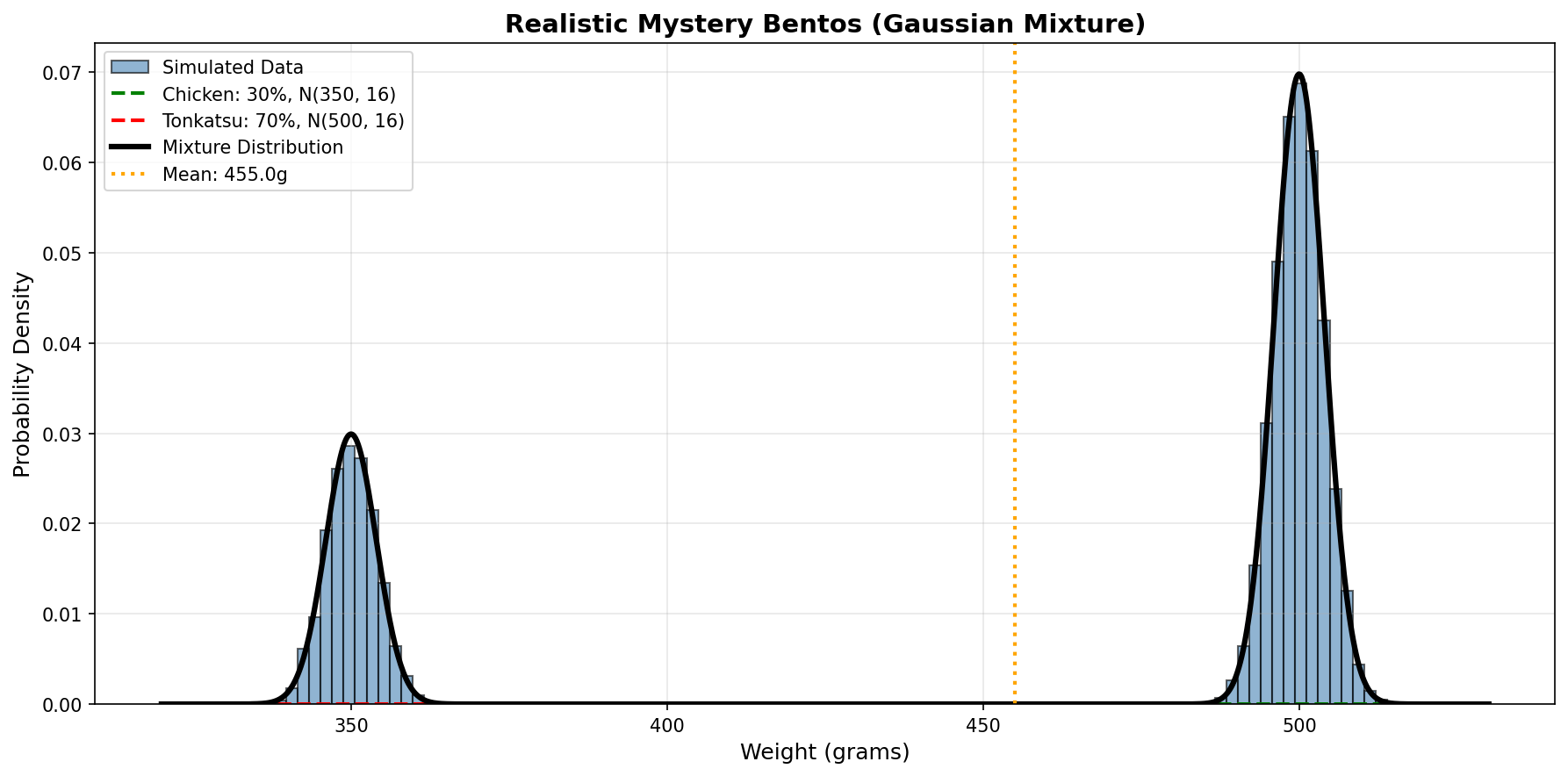
Now the two peaks have natural variation (they’re not perfect spikes at 500g and 350g), but the average still falls in the valley where no individual bento lives!
Why the Gaussian Distribution is Special
1. Central Limit Theorem
One reason Gaussians appear everywhere: the Central Limit Theorem says that when you sum many independent random variables, the result approaches a Gaussian distribution, regardless of what the individual variables look like.
Example: A bento’s weight might be determined by:
- Rice amount (varies randomly)
- Main protein amount (varies randomly)
- Vegetables amount (varies randomly)
- Sauce amount (varies randomly)
- Container variations (varies randomly)
Even if each component isn’t Gaussian, their sum (the total weight) tends toward Gaussian!
2. Maximum Entropy Distribution
Given only a mean and variance, the Gaussian has maximum entropy (it makes the fewest additional assumptions). This makes it the “most unassuming” distribution.
3. Conjugate Prior (Coming Soon!)
In Chapter 4, you’ll learn that the Gaussian has special mathematical properties that make Bayesian inference tractable. When you observe Gaussian data and use a Gaussian prior, the posterior is also Gaussian. This “conjugacy” makes computation elegant.
4. Additive Properties
If X ~ N(μ₁, σ₁²) and Y ~ N(μ₂, σ₂²) are independent, then:
- X + Y ~ N(μ₁ + μ₂, σ₁² + σ₂²)
Means add, variances add. Beautiful!
Computing Probabilities with the Gaussian CDF
Just like with the uniform distribution, we can compute probabilities using the CDF:
Question: What’s the probability a tonkatsu bento weighs more than 503g?
| |
Output:
P(weight > 503g) = 0.0668About 6.68% of bentos weigh more than 503g.
Verify with simulation:
| |
Output:
Simulated P(weight > 503g) = 0.0424This is roughly $0.7 \times 0.0668 \approx 0.047$ — the analytic $0.0668$ is the chance within the tonkatsu cluster, and only ~70% of bentos are tonkatsu, so the overall fraction is lower. (The two would match exactly if every bento were tonkatsu.)
Standard Normal Distribution
A special case: standard normal has μ = 0 and σ² = 1, written as N(0, 1).
Any Gaussian X ~ N(μ, σ²) can be standardized:
$$Z = \frac{X - \mu}{\sigma}$$
Then Z ~ N(0, 1). This “Z-score” tells you how many standard deviations X is from the mean.
Example: A 504g tonkatsu bento:
| |
This bento is exactly 2 standard deviations above the mean. Using the 68-95-99.7 rule, we know that’s in the 95th percentile range (unusual but not extremely rare).
Practice Problems
Problem 1: Student Test Scores
Test scores follow N(75, 100) (mean 75, variance 100, so std dev = 10).
a) What percentage of students score between 65 and 85?
b) What score is at the 90th percentile?
c) Simulate 1000 students and verify your answers.
Show Solution
| |
Output:
a) P(65 < score < 85) = 68.3%
b) 90th percentile score: 87.8
c) Simulated P(65-85): 68.1%
Simulated 90th percentile: 87.4Problem 2: Quality Control
A factory produces bolts with length N(50, 0.25) mm (mean 50mm, std dev 0.5mm). Bolts are rejected if they’re outside 49-51mm.
a) What percentage of bolts are rejected?
b) The factory wants to reduce rejects to under 1%. What must the standard deviation be?
Show Solution
| |
Output:
a) Rejection rate: 4.6%
b) Required std dev: 0.388mm
New rejection rate: 1.00%What’s Next?
We now understand:
- The Gaussian distribution and its parameters
- The 68-95-99.7 rule
- How to work with Gaussians in GenJAX
- Why Gaussians appear everywhere
But here’s a question: What if we don’t know μ and σ²?
In Chapter 4, we’ll learn Bayesian learning: how to estimate these parameters from data, starting with prior beliefs and updating them as we observe bento weights. This is where probabilistic programming really shines!
Key Takeaways
- Gaussian distribution: The “bell curve” described by mean (μ) and variance (σ²)
- 68-95-99.7 rule: Approximately 68%/95%/99.7% of data within 1/2/3 standard deviations
- Ubiquity: Central Limit Theorem makes Gaussians appear everywhere
- GenJAX:
normal(mu, sigma)samples from N(μ, σ²) - Simulation: Monte Carlo verification matches theoretical probabilities
Next Chapter: Bayesian Learning with Gaussians →