Setup & the Framework
What you’re bringing with you
This chapter changes exactly one thing about what you already know — and it is worth saying up front what stays the same, because almost everything does.
📦 You already have all of these
Everything in this chapter is built out of tools you have used in earlier chapters:
- Bayes’ rule as posterior ∝ likelihood × prior. You have used this in every chapter that involved learning — updating a belief by multiplying a prior by a likelihood and renormalizing. ← Review in Chapter 4
- The predictive distribution — “given what I’ve seen, what should I expect for the next observation?” You met the posterior-predictive in Chapter 4 (“what weight should I expect for the next bento?”). ← Review in Chapter 4
- Conditioning = restricting to what’s consistent with the data. Observing something throws away every possibility that disagrees with it, and you renormalize over what survives. ← Review in the GenJAX tutorial, Chapter 4
- Categorization — computing P(category | observation) when an item could belong to one of several groups. You met this with two Gaussians in the Chapter 4 preview and the Gaussian-clusters work. ← Review in Chapter 5
The one new idea: in every one of those chapters, the unknown you reasoned about was either a number (a mean μ) or a yes/no fact (is this bento tonkatsu? is the taxi blue?). In this chapter, the unknown becomes a set — a rule about which things share a property. That single shift — from “which value?” to “which set?” — is the whole content of Bayesian generalization. The machinery for reasoning about it is the machinery you already have.
The golden sticker
Chibany has been receiving bentos for months, and lately they have noticed something odd. Some bentos arrive with a tiny golden sticker on the side. Others don’t.
Chibany has no idea what the sticker means. Maybe it marks the day of the week the bento was made. Maybe it marks a particular chef. Maybe it’s a price tier, or a loyalty reward, or something else entirely. All Chibany gets to see is which bentos have the sticker and which don’t.
Being a probabilist, Chibany decides to figure it out the only way they can: by guessing rules and watching which guesses survive. They write down every plausible rule the sticker might follow —
“only on Mondays” “only tonkatsu bentos” “only bentos heavier than 400 g” “every bento” (maybe the sticker means nothing at all)
— and then they wait. As more sticker’d bentos arrive, some rules will keep fitting and others will be ruled out or made to look unlikely. Whatever rules are still standing after the data is what Chibany should believe.
That is the entire idea of this chapter, and it already contains its three moving parts:
- The golden sticker is a novel property — something we want to predict for new bentos.
- Each rule is a hypothesis: and notice that a rule is really just a set of bentos — “only Mondays” is the set of all Monday bentos, “every bento” is the set of all of them.
- The rules still standing after Chibany sees some data form a posterior over hypotheses.
The question Chibany actually wants to answer is a prediction: I see one bento with a golden sticker — should I expect the next one to have it too? We will build up to answering exactly that.
The shift in one sentence
A hypothesis in this chapter is a rule, and a rule is a set — the set of things the rule says have the property. Hold onto “a hypothesis is a set”; everything else follows from it.
From “which event?” to “which set?”
Before we write down any general framework, let’s cross the one genuinely new idea on the smallest possible example — because the leap from “the unknown is a yes/no fact” to “the unknown is a set” is the only thing here you haven’t done before.
Start with something you’ve already solved
Recall the taxicab problem from the GenJAX tutorial (Chapter 4). A taxi was involved in an accident at night. The unknown was a single yes/no fact: was the taxi blue or green? In that chapter we wrote the hypothesis with a capital $H$; here we’ll use a lowercase $h$ for one hypothesis (one candidate answer), because in a moment we’ll have a whole list of them — $h_1, h_2, \dots$ — and want a clean symbol for a single member. So, two competing possibilities,
$$h \in \{\text{blue},\ \text{green}\}.$$
and Bayes’ rule ranked them: a prior over the two colors, a likelihood for the witness’s report, and a posterior that combined them. Two hypotheses, and we asked which one the data favored.
“Blue” was a set all along
Here is the small reframing that opens up the whole chapter. When we said the taxi was “blue,” what we really meant was that it belonged to the set of all blue taxis. “Green” is the set of all green taxis. An event — in the sense you learned in the very first tutorial — is just a subset of the possible outcomes. So the hypotheses in the taxicab problem were sets the entire time. We simply never needed to look at them that way, because the two sets didn’t overlap and we only cared which one the taxi fell into.
What’s new: overlapping sets of different sizes
Generalization is what happens when we take that same “which set?” question and let the sets get interesting:
- the candidate sets can overlap — a single bento can satisfy “only Mondays” and “every bento” at once, so one item can belong to many hypotheses; and
- the candidate sets can differ in size — “only tonkatsu bentos” is a small, specific set, while “every bento” is the largest set possible.
That’s the only genuinely new wrinkle. Once hypotheses are sets that overlap and vary in size, “which set does the property follow?” becomes a much richer question than “blue or green?” — but it is answered with the exact same Bayes’ rule.
A two-rule example you can hold in your head
Let’s make it concrete with just two rules, so the whole posterior fits on one line. Chibany lines up a tiny menu of four bentos and numbers them by weight, lightest to heaviest — so bento 0 is the lightest, bento 3 the heaviest. Two candidate rules for the golden sticker are on the table:
- Rule A — “the two lightest bentos”: the set $\{0, 1\}$.
- Rule B — “the lighter half”: the set $\{0, 1, 2\}$.
Both rules contain bento 0 and bento 1; they differ only on bento 2 (in B, not in A) and agree that bento 3 (the heaviest) is out. Suppose Chibany starts with no reason to prefer either rule — a flat (uniform) prior, $p(A) = p(B) = 0.5$ — and then observes one sticker’d bento: bento 1.
Before we can update, we need a likelihood — a rule for how probable the observation is under each hypothesis. We’ll use the simplest one, called weak sampling:
📌 Keep in mind: weak sampling (our first likelihood)
Weak sampling says the likelihood is all-or-nothing: a hypothesis that contains every observed item is consistent with the data (likelihood 1), and a hypothesis that misses any observed item is impossible (likelihood 0). In other words, observing data simply keeps the rules consistent with it and throws out the rest — exactly the “conditioning = restricting the outcome space” move from the taxicab problem.
Formally, writing $h$ for a hypothesis (a set) and $X$ for the observed items, the weak-sampling likelihood is
$$p(X \mid h) = \begin{cases} 1 & \text{if every observed item is in } h \\ 0 & \text{otherwise} \end{cases}$$
(Later, in §6, we’ll meet a sharper likelihood — strong sampling — that also prefers smaller rules. For now, weak sampling is all we need.)
Apply it here: bento 1 is in both Rule A and Rule B, so under weak sampling both have likelihood 1 — neither is ruled out. Posterior ∝ likelihood × prior, so each rule’s posterior is $1 \times 0.5 = 0.5$ (then normalized), and the belief stays split evenly:
$$p(A \mid \text{bento 1 has the sticker}) = p(B \mid \dots) = 0.5.$$
Now Chibany can answer the prediction they actually care about. Is the next bento — say, bento 2 — likely to have the sticker? Bento 2 is in Rule B but not in Rule A. So only the rules that contain bento 2 vote “yes,” weighted by how much we now believe each rule:
$$p(\text{bento 2 has the sticker} \mid \text{data}) = \underbrace{p(B \mid \text{data})}_{\text{B contains 2}} = 0.5.$$
Bento 0, by contrast, is in both surviving rules, so its predicted probability is $p(A) + p(B) = 1.0$ — we’re certain. And bento 3 is in neither, so its predicted probability is $0$.
You have just done Bayesian generalization. The prediction for a new item is the total belief sitting on the rules that contain it. Everything else in this chapter — bigger rule-sets, the “suspicious coincidence” that makes smaller rules win, continuous rules — is this same calculation at larger scale.
The same thing in code
Because there are only two hypotheses, we can do something even simpler than the taxicab’s sampling: we can write down both rules, score each one by prior × likelihood (exactly Bayes’ rule), and normalize. With a handful of hypotheses there is no need to sample at all — we just check every rule directly. (Later in the chapter, when the rules number in the dozens, this same “score every rule and normalize” idea is all we’ll need.)
We represent each rule as a row of 0s and 1s — a membership list, the same 0/1 “is it in the set?” idea you used to describe an event in the first tutorial:
| |
Output:
posterior: Rule A = 0.5 Rule B = 0.5
predicted P(sticker) for bento 0 = 1.0
predicted P(sticker) for bento 1 = 1.0
predicted P(sticker) for bento 2 = 0.5
predicted P(sticker) for bento 3 = 0.0The printed predictions match what we worked out by hand: bento 0 is certain (in both rules), bento 2 is a coin flip (in one rule), bento 3 is impossible (in neither). Every line of that code is Bayes’ rule and a membership lookup — no new machinery, just the rules written as 0/1 lists.
Why no @gen model here?
In earlier chapters we wrote a @gen generative model and let GenJAX do the inference by sampling
(generate plus importance weights, as in the taxicab problem). That still works here — and we could write
@gen def which_rule(): rule = categorical(...) @ "rule". But with only a few hypotheses, sampling is
overkill: scoring every rule directly, as above, is both exact and easier to read. We’ll bring the @gen
generative view back when it earns its keep — when the hypotheses are too numerous to sample comfortably and
we want to generate sticker’d bentos rather than just score rules.
What just happened
You reframed a yes/no question (“blue or green?”) as a question about sets (“which rule?”), let the sets overlap and vary in size, and predicted a new item by adding up the belief on every rule that contains it. That is the engine of the whole chapter. The next sections give it a name, scale it up, and explain why — under the right assumptions — smaller rules end up winning.
A target to aim for: Shepard’s law
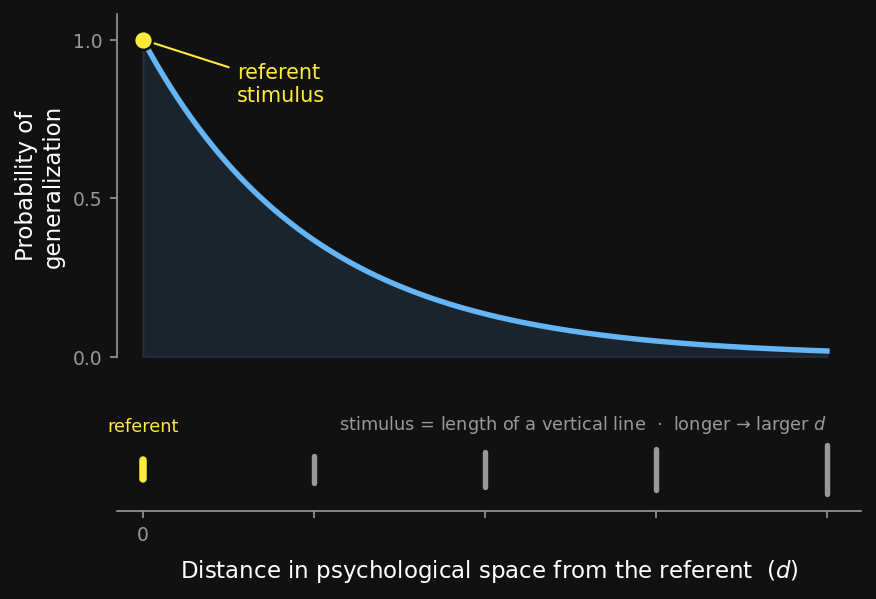
Before we scale the two-rule example up into a general method, it helps to know what a good method should produce. There is a striking empirical fact about how people (and animals) generalize, and any model worth its salt should reproduce it.
In a classic 1987 paper, Roger Shepard (Shepard, 1987) measured how willing people are to extend a property from one stimulus to another as the two stimuli grow more different. The pattern was remarkably consistent across senses and species: the probability of generalizing falls off smoothly as the two stimuli get further apart, and it falls off at a particular rate — an exponential one. Writing $d$ for the distance between two stimuli, then in suitable units
$$g(d) = e^{-d},$$
where $g$ is the probability of generalizing. (More generally the rate can differ, $g(d) = e^{-d/\tau}$ for some scale $\tau$; we set $\tau = 1$ here to keep the picture simple.) Here $e^{-d}$ is just a curve that starts at 1 when $d = 0$ (no distance, certain to generalize) and decays smoothly toward 0 as $d$ grows — you’ve seen the $\exp(-\ldots)$ form before, inside the Gaussian bell curve in Chapter 3, where it likewise equals 1 at the center and decays to zero (the Gaussian’s is a bell, Shepard’s is a sharper cusp — same “exponential of a negative quantity,” different curve). We will meet $e^{-\lambda s}$ as a full probability distribution — the exponential distribution — later in the chapter, in §8; for now it is only a curve.
One subtlety: distance in psychological space
The distance $d$ that matters is not raw physical distance — it is perceived distance, the distance after the mind has represented the stimulus. Two colors that are far apart on a wavelength scale might feel close; two musical notes an octave apart feel related despite a large frequency gap. Shepard’s law is about the mind’s internal “psychological space,” not the physical measurement. We won’t need to construct that space in this chapter — but it’s why the law is stated in terms of $d$, a perceived distance, rather than physical units.
Shepard’s law is descriptive: it tells us generalization decays exponentially, but not why. That “why” is exactly what the framework we’re about to build delivers. By §8 we will not assume the exponential — we will watch it emerge from the model, falling out of the posterior-weighted vote you already met (and, as Shepard first showed, it can be proved analytically for the idealized case). Keep $g(d) = e^{-d}$ in the back of your mind as the target.
The framework, named
We now have everything we need to state the method in general — and because §2 already made “a hypothesis is a set” concrete on two rules, none of the symbols below should feel abstract. Each one is something you have already used, pointed at a slightly new object. The framework in this form — generalization as Bayesian inference over a hypothesis space of consequential sets, unifying Shepard’s law with similarity- and rule-based generalization — is due to Tenenbaum & Griffiths (2001), building on Shepard’s normative account.
Notation lock-in
We will use five symbols throughout the rest of the chapter. Take a moment with them now; each is defined here before it appears in any formula.
- $h$ — a single hypothesis: one candidate rule, i.e. one set of items. (In the taxicab problem this was “blue” or “green”; now it can overlap other hypotheses and vary in size, as in §2.)
- $\mathcal{H}$ — the hypothesis space: the whole list of candidate hypotheses under consideration. (The script letter $\mathcal{H}$ is new notation; read it as “the collection of all the $h$’s.”)
- $X = \{x_1, \dots, x_n\}$ — the observed examples: the $n$ items we’ve seen to have the property (the sticker’d bentos; the example numbers in the number game below).
- $y$ — a novel item we want to judge: does it have the property?
- $C$ — the true (unknown) set the property actually picks out. This is not one of our $h$’s — it is the truth our hypotheses are guesses at. Our whole goal is to predict the event “$y \in C$” (is $y$ really in the true set?) from the examples $X$.
The three ingredients — exactly Bayes’ rule, new object
These are the same three pieces from Chapter 4, now applied to hypotheses that are sets:
- Prior $p(h)$ — how plausible each rule is before seeing data.
- Likelihood $p(X \mid h)$ — how probable the observed examples are if $h$ were the true rule.
- Posterior $p(h \mid X) \propto p(X \mid h) p(h)$ — our updated belief in each rule after the data. Identical in form to every Bayesian update you’ve done; only the meaning of $h$ has changed.
The hypothesis space is a prior
Here is a consequence worth pausing on. Any rule you leave out of $\mathcal{H}$ has, in effect, prior probability zero — no amount of data can ever revive it. So the very choice of which hypotheses to consider is already a strong prior belief, baked in before a single observation. We’ll return to this in §9 (No Free Lunch), where it turns out to be the entire reason generalization is possible at all. For now, just notice: what you refuse to consider, you can never learn.
The indicator: a compact way to ask “is $y$ in $h$?”
One more symbol, and it is one you have almost seen. To write the prediction rule compactly we need a way to say “1 if $y$ is in the set $h$, and 0 otherwise.” We write that as
$$\mathbf{1}[y \in h] = \begin{cases} 1 & \text{if } y \in h \\ 0 & \text{if } y \notin h \end{cases}$$
This indicator is nothing new in substance: it is exactly the 0/1 membership you already used to write a rule as a row of 0s and 1s in §2. If $h$ is a row of the membership matrix, then $\mathbf{1}[y \in h]$ is simply the entry in column $y$ of that row. We give it a symbol only so the prediction formula in §5 fits on one line.
The hypothesis space in code
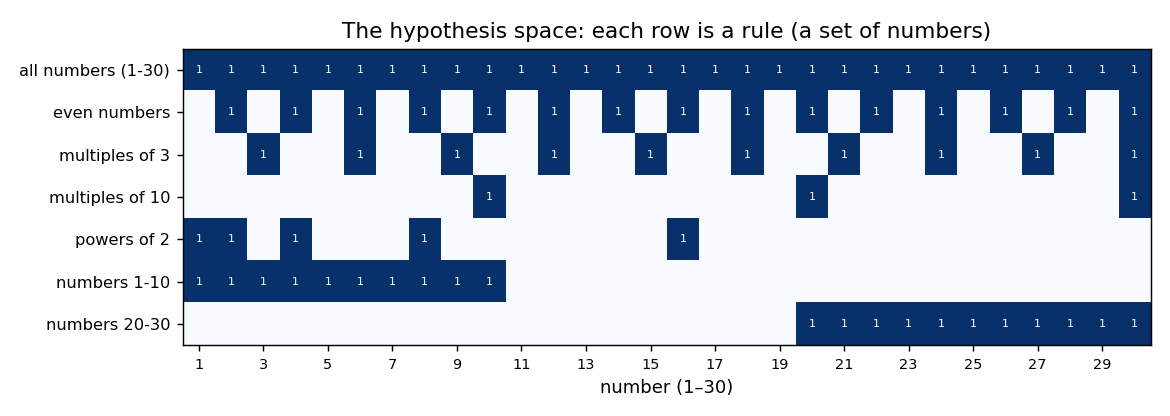
Let’s build a real, slightly bigger hypothesis space and use it for the rest of the chapter. We’ll play Tenenbaum’s number game: someone has a hidden rule that picks out some of the numbers from 1 to 30, you see a few example numbers that fit it, and you judge which other numbers fit. (We use 1–30 rather than the classic 1–100 so the whole space fits in one picture.) Each hypothesis is a rule about which numbers share the property — written, just like the two rules in §2, as a row of 0s and 1s over the numbers 1–30.
We’ll consider a small, mixed set of seven candidate rules: a few “multiples of $k$,” “powers of 2,” two magnitude intervals, and the catch-all “all numbers.” Rather than type out 7 × 30 ones and zeros by hand, we build each row from its defining test:
| |
Which is rows, which is columns? (reading a 2-D array)
H is a 2-D array — a stack of rows. The mapping is always the same and worth pinning down once: the first
index is the row, the second is the column. Here each row is one rule (h0, h1, … stacked top to bottom)
and each column is one number (column 0 is the number 1, column 1 is the number 2, …, column 29 is the
number 30). So H[i, j] answers “does rule $i$ include number $j{+}1$?” For example H[3, 9] is row 3
(“multiples of 10”), column 9 (the number 10) — a 1, because 10 is a multiple of 10. (Watch the off-by-one:
the number $n$ lives in column $n-1$, since Python counts columns from 0.)
This matrix H is the whole hypothesis space $\mathcal{H}$ — seven rules over thirty numbers — stacked into
rows. Rule h0 is a catch-all — “all numbers,” the hypothesis that every number has the property. Because
it contains everything, no observation can ever rule it out; it is always left standing. Including it is
deliberate, and we’ll see in §6 and §9 why it matters.
We can see the whole space at a glance — each row a rule, each lit cell a number that rule includes:
New idiom: vmap over the rows of a matrix
In earlier chapters you used jax.vmap to run a model once per random key — the same computation across
many particles. There is a second way to use it that we’ll lean on here: running a computation once per row
of a matrix. For example, the size $|h|$ of a hypothesis is just how many 1s are in its row, so we can get
the size of every rule at once:
| |
Output:
|h| for all numbers = 30
|h| for even numbers = 15
|h| for multiples of 3 = 10
|h| for multiples of 10 = 3
|h| for powers of 2 = 5
|h| for numbers 1-10 = 10
|h| for numbers 20-30 = 11Same vmap you know — “do this for each of them” — just mapping over rows of H instead of over keys. We’ll
use exactly this pattern in §5 to score every hypothesis at once. (The size $|h|$ itself becomes important in
§6.)